Milvus是一套开源的向量搜索引擎,为海量特征向量的近似最近邻搜索(ANNS)而设计。相比 Faiss 和 SPTAG 这样的算子库,Milvus 提供完整的向量数据更新,索引与查询框架。Milvus 利用 GPU 进行索引加速与查询加速,能大幅提高单机性能。Milvus 向量搜索引擎可以广泛地和各种深度学习模型进行整合,简化 AI 应用落地的难度。Milvus遵守Apache 2.0开源协议。
在目前大部分的 AI 应用场景下,都可以使用 Milvus 来搭建智能应用系统:
图片识别
以图搜图,通过图片检索图片。具体应用例如:车辆检索和商品图片检索等。
视频处理
针对视频信息的实时轨迹跟踪
自然语言处理
基于语义的文本检索和推荐,通过文本检索近似文本。
声纹匹配,音频检索。
文件去重,通过文件指纹去除重复文件。
---------------------------------------------------------
A cloud-native vector database, storage for next generation AI applications .
Milvus is an open-source vector database built to power embedding similarity search and AI applications. Milvus makes unstructured data search more accessible, and provides a consistent user experience regardless of the deployment environment.
Milvus 2.0 is a cloud-native vector database with storage and computation separated by design. All components in this refactored version of Milvus are stateless to enhance elasticity and flexibility. For more architecture details, see Milvus Architecture Overview.
Milvus was released under the open-source Apache License 2.0 in October 2019. It is currently a graduate project under LF AI & Data Foundation.
Key features
Millisecond search on trillion vector datasets
Average latency measured in milliseconds on trillion vector datasets.Simplified unstructured data management
Reliable, always on vector database
Milvus’ built-in replication and failover/failback features ensure data and applications can maintain business continuity in the event of a disruption.Highly scalable and elastic
Component-level scalability makes it possible to scale up and down on demand. Milvus can autoscale at a component level according to the load type, making resource scheduling much more efficient.Hybrid search
In addition to vectors, Milvus supports data types such as Boolean, integers, floating-point numbers, and more. A collection in Milvus can hold multiple fields for accommodating different data features or properties. Milvus pairs scalar filtering with powerful vector similarity search to offer a modern, flexible platform for analyzing unstructured data. Check for examples and boolean expression rules.Unified Lambda structure
Milvus combines stream and batch processing for data storage to balance timeliness and efficiency. Its unified interface makes vector similarity search a breeze.Community supported, industry recognized
With over 1,000 enterprise users, 9,000+ stars on GitHub, and an active open-source community, you’re not alone when you use Milvus. As a graduate project under the , Milvus has institutional support.Quick start
Start with Zilliz Cloud
Zilliz Cloud is a fully managed service on cloud and the simplest way to deploy LF AI Milvus®, See Zilliz Cloud Quick Start Guide and start your free trial.
Install Milvus
Build Milvus from source code
Check the requirements first.
Linux systems (Ubuntu 20.04 or later recommended):
go: >= 1.18
cmake: >= 3.18
gcc: 7.5
MacOS systems with x86_64 (Big Sur 11.5 or later recommended):
go: >= 1.18
cmake: >= 3.18
llvm: >= 15
MacOS systems with Apple Silicon (Monterey 12.0.1 or later recommended):
go: >= 1.18 (Arch=ARM64)
cmake: >= 3.18
llvm: >= 15
Clone Milvus repo and build.
# Clone github repository.
$ git clone https://github.com/milvus-io/milvus.git
# Install third-party dependencies.
$ cd milvus/
$ ./scripts/install_deps.sh
# Compile Milvus.
$ make
For the full story, see developer's documentation.
IMPORTANT The master branch is for the development of Milvus v2.0. On March 9th, 2021, we released Milvus v1.0, the first stable version of Milvus with long-term support. To use Milvus v1.0, switch to branch 1.0.
Milvus 2.0 vs. 1.x: Cloud-native, distributed architecture, highly scalable, and more
See Milvus 2.0 vs. 1.x for more information.
Real world demos
 |
 |
 |
| Image search | Chatbots | Chemical structure search |
|---|
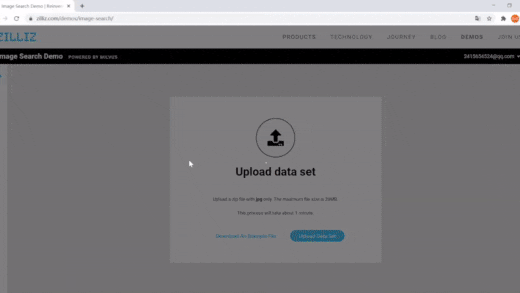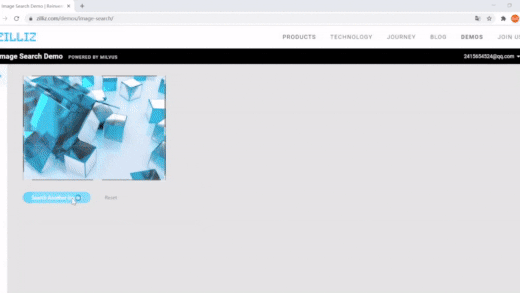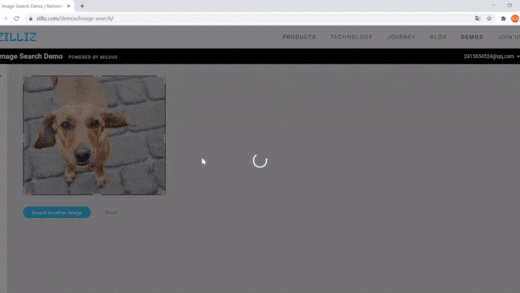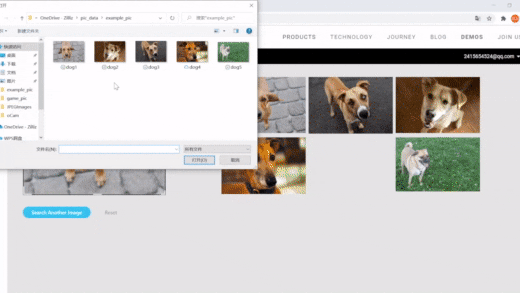
Image Search
Images made searchable. Instantaneously return the most similar images from a massive database.
Chatbots
Interactive digital customer service that saves users time and businesses money.
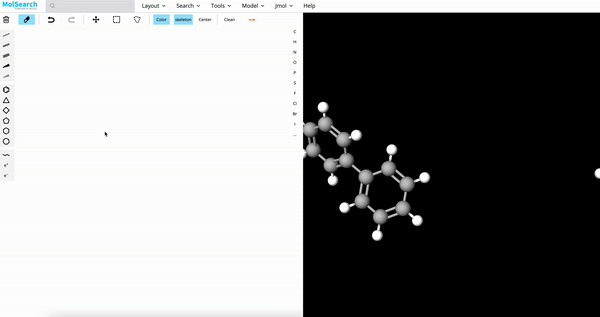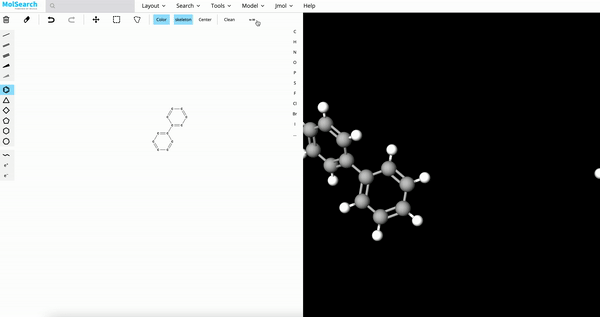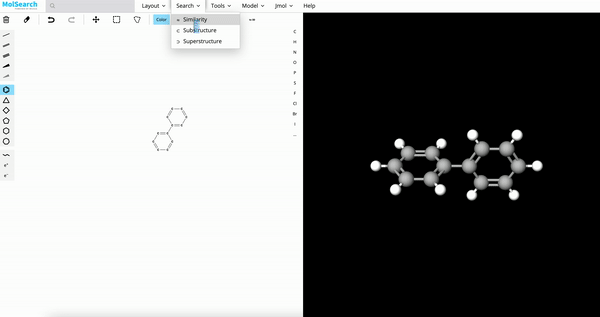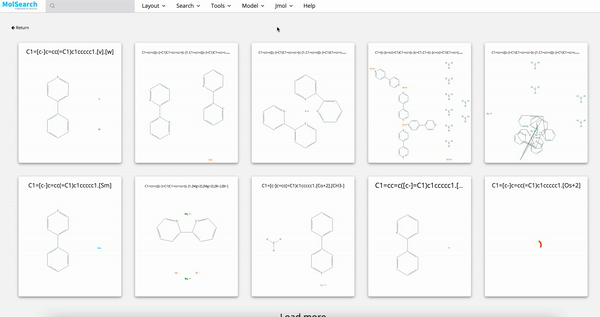
Chemical Structure Search
Blazing fast similarity search, substructure search, or superstructure search for a specified molecule.
Bootcamps
Milvus bootcamp is designed to expose users to both the simplicity and depth of the vector database. Discover how to run benchmark tests as well as build similarity search applications spanning chatbots, recommendation systems, reverse image search, molecular search, and much more.
Documentation
For guidance on installation, development, deployment, and administration, check out Milvus Docs. For technical milestones and enhancement proposals, check out milvus confluence
SDK
The implemented SDK and its API documentation are listed below:
Attu
Attu provides an intuitive and efficient GUI for Milvus.
Community
Join the Milvus community on Slack to share your suggestions, advice, and questions with our engineering team.

You can also check out our FAQ page to discover solutions or answers to your issues or questions.
Subscribe to Milvus mailing lists:
Acknowledgments
Milvus adopts dependencies from the following:
- Thanks to FAISS for the excellent search library.
- Thanks to etcd for providing great open-source key-value store tools.
- Thanks to Pulsar for its wonderful distributed pub-sub messaging system.
- Thanks to RocksDB for the powerful storage engines.
Milvus is adopted by following opensource project:
- Towhee a flexible, application-oriented framework for computing embedding vectors over unstructured data.
- Haystack an open source NLP framework that leverages Transformer models
- Langchain Building applications with LLMs through composability
- GPTCache a library for creating semantic cache to store responses from LLM queries.
from
https://github.com/milvus-io/milvus
-------------------------------------------
Milvus Python SDK




Python SDK for Milvus. To contribute code to this project, please read our contribution guidelines first. If you have some ideas or encounter a problem, you can find us in the Slack channel #py-milvus.
Compatibility
The following collection shows Milvus versions and recommended PyMilvus versions:
| Milvus version | Recommended PyMilvus version |
|---|---|
| 1.0.* | 1.0.1 |
| 1.1.* | 1.1.2 |
| 2.0.* | 2.0.2 |
| 2.1.* | 2.1.3 |
| 2.2.* | 2.2.0 |
Installation
You can install PyMilvus via pip or pip3 for Python 3.6+:
$ pip3 install pymilvus
You can install a specific version of PyMilvus by:
$ pip3 install pymilvus==2.2.0
You can upgrade PyMilvus to the latest version by:
$ pip3 install --upgrade pymilvus
FAQ
Q1. How to get submodules?
A1. The following command will get the protos matching to the generated files, for protos of certain version, see milvus-proto for details.
$ git submodule update --init
Q2. How to generate python files from milvus-proto?
Before generating python files, please install requirements in requirements.txt
A2.
$ make gen_proto
Q3. How to use the local PyMilvus repository for Milvus server?
A3.
$ python setup.py install
Documentation
Documentation is available online: https://milvus.io/api-reference/pymilvus/v2.2.3/About.md
Developing package releases
The commits on the development branch of each version will be packaged and uploaded to Test PyPI.
The package name generated by the development branch is x.y.z.dev, where is the number of commits that differ from the most recent release.
-
For example, after the release of 2.0.1, two commits were submitted on the 2.0 branch. The version number of the latest commit of 2.0 branch is 2.0.2.dev2.
-
For example, after the release of 2.0.1, 10 commits were submitted on the master branch. The version number of the latest commit of master branch is 2.1.0.dev10.
To install the package on Test PyPi, you need to append --extra-index-url after pip, for example:
$ python3 -m pip install --extra-index-url https://test.pypi.org/simple/ pymilvus==2.1.0.dev66
from
https://github.com/milvus-io/pymilvus